728x90
반응형
https://deep-learning-study.tistory.com/567, arxiv.org/pdf/2104.00298.pdf를 참고했습니다.
EfficientNetV2
- 2019년에 나온 EfficientNetV1의 후속작으로, EfficientNetV2, Smaller Models and Faster Training
- EfficentNetV2(이하 ENV2)는 빠른 학습에 집중한 모델
- 자연어 처리 분야에서 GPT-3은 엄청 큰 데이터셋으로 학습 시켜 뛰어난 성능을 보임, 하지만 GPT-3은 수천개의 TPU로 학습시켜 retain과 개선이 어려움
- training efficiency는 최근 큰 관심을 받고 있음
- NFNet(2021), BotNet(2021), ResNet-Rs(2021)등 모두 training efficiency를 향상시키기위해 제안된 모델
- 위 모델과 EV2모델을 비교했을 때, EV2의 파라미터 수가 월등히 적음 => ENV2가 효율적인 모델

위 그림을 보면 ENV2는 ENV1과 비교했을 때 4배 빠른 학습 속도와 6.8배 적은 파라미터 수로 비슷한 정확도 달성
- 논문에서 설명하느 학습속도를 느리게 하는 3가지 요소
- 큰 이미지 : 큰 이미지로 학습하면 학습속도가 느림
- 초기 layer에서 depthwise convolution은 학습 속도에 악영향을 줌
- 모든 stage를 동일한 비율로 scailing up하는 것은 최선의 선택이 아님
위 3가지를 해결하기 위해 progressive learning과 fused-MBConv, non-uniform전략 도입
1. Training with very large image sizes is slow
- 큰 입력 이미지로 학습을 하면, 메모리가 제한되어 있기 때문에 batch size를 작게 해야함 -> 학습속도가 느려지게함
- 입력 이미지를 작게 하는 것 : 연산량 감소, 큰 배치사이즈를 사용할 수 있게 함
- FixEfficientNet에서 train 입력 이미지를 test 입력 이미지보다 작게 학습해서 성능을 향상시킴
- ENV2는 좀 더 나은 학습방법인 Progressive Learning을 제안
1.1. Progressive Learning
- Progressive Learning은 training 시, 이미지의 크기를 점진적으로 증가시키는 것
- 이 방법은 학습속도를 빠르게 하기 위해 사용하지만 정확도가 감소하는 문제점 존재
- 기존의 방법은 이미지 크기에 따라 모두 동일한 정규화(dropout, augmentation)을 적용
- EN은 이미지 크기에 따라 정규화 방법을 다르게 설정해 정확도가 감소하는 문제 해결
- 저자는 progressive learing을 적용했을 때, 정확도가 감소하는 이유는 입력 이미지 크기에 따라 동일한 정규화를 사용하기 때문이라고 함
- => 입력 이미지가 작을 때는 약한정규화 ex) augmentation 확률을 낮게 설정
- => 입력이미지가 클 때는 오버피팅을 방지하기 위해 강한 정규화를 적용 ex) aumentation 확률을 좀 더 높게 설정 or dropout 확률을 높임

위 표는 실험결과) 입력이미지가 커질 수록 RandAug magnitude를 높게 설정하면, 성능이 향상되는 것을 확인할 수 있음
1.2. 논문에서 사용하는 3가지 정규화
- dropout
- randAugment
- Mixup

ImageNet dataset에 적용하는 Progressing training setting : 입력이미지가 커질 수록 최소값에서 최대값으로 점진적으로 증가

Progressive learning을 다른 모델에 적용해도 성능이 향상 됨

2. Depthwise convolution are slow in early layers

- Depthwise Convolution은 MobileNetV1과 Xception에서 제안된 방법 : 효과가 입증되어 최신모델까지 이용하고 있음
- Depthwise Convolution은 conv 연산량을 낮춰주어 제한된 연산량 내에 더 많은 filter을 사용할 수 있는 이점이 있음
- 하지만 Depthwise Convolution은 modern accelator을 활용하지 못하기 때문에 학습 속도를 느리게 함
- => stage 1-3에서는 MBConv 대신에 Fused-MBConv를 사용함
- Fused-MBConv : MBConv의 1X1 conv + 3X3 depthwise conv 대신에, 하나의 3X3 Conv를 사용하는것
- 모든 stage에 FusedConv를 적용하니 오히려 학습 속도가 느려졌다고 함 => 초기의 stage에만 Fused-MBConv 사용

3. Equally scaling up every stage is sub-optimal
- EN은 copound scaling으로 모든 스테이지를 동일하게 scailing up 했음 ex) depth 상수가 2이면 stage의 layer가 2배가 되었음
- 하지만 stage들이 training speed에 기여하는 정도가 다다름 => non-uniform scaling strategy를 사용함
- non-uniform scaling strategy는 stage가 증가할수록 layer가 증가하는 정도를 높이는 것, 증가하는 정도는 heuristic하게 결정
- compound scaling에서 maximum이미지 사이즈를 작은 값으로 제한 : progressive learning은 학습이 진행될 수록 입력 이미지 크기가 커지므로 memory 사용량이 점점 커져 학습 속도를 느리게 하는 문제를 해결하기 위함
ENV2 Architecture

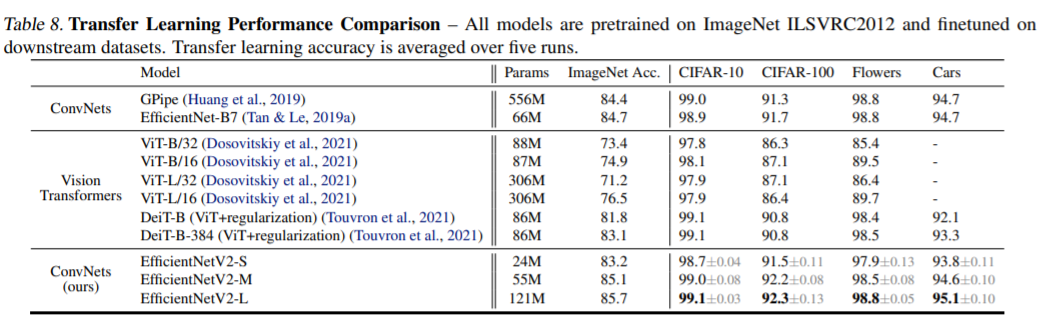
Performance


728x90
반응형
'AI & 데이터 분석 > 관련 개념 정리' 카테고리의 다른 글
| Efficient Net이 뭐지? (0) | 2021.10.26 |
|---|---|
| AutoML MNAS Mobile Framework가 뭐지? (0) | 2021.10.26 |
| AI 데이터 분석 기초 용어 정리 (0) | 2021.04.24 |